Boris Batteux
|
0
|
October 21, 2021


Last year we released D-810, our IDA-Pro plugin that we used to analyze obfuscated binaries. In last blog post, we focused on how D-810 can be used to remove the instruction level obfuscation. This time, we wanted to explain how D-810 can be used to deal with control flow flattening.
We start by giving a quick overview of what is control flow flattening and how it can be removed. Then, we describe the components of D-810 which can be used to remove this type of obfuscation:
Finally, we demonstrate how D-810 can be used and configured to remove the control flow flattening generated by Tigress obfuscator.
The code of D-810 can be found here and the samples used in this blog post can be found here.
What is Control Flow Flattening?
The goal of flattening is to hide the original control flow of a function by putting all the function basic blocks on the same level. For instance, before this obfuscation pass, the graph of a function can look like that:
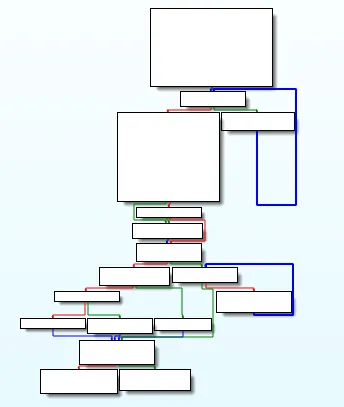
Depending on the obfuscator used (and its configuration), the graph of the obfuscated function can look like the following ones:
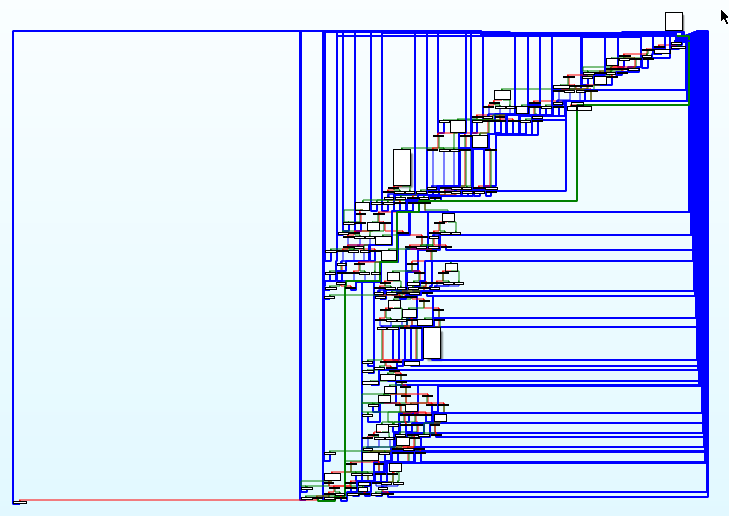


In practice, this obfuscation technique is quite annoying as it prevents us from quickly understanding a function. For example, here is an extract of the decompiled code of the function obfuscated with Tigress Flatten (using the switch dispatcher method):
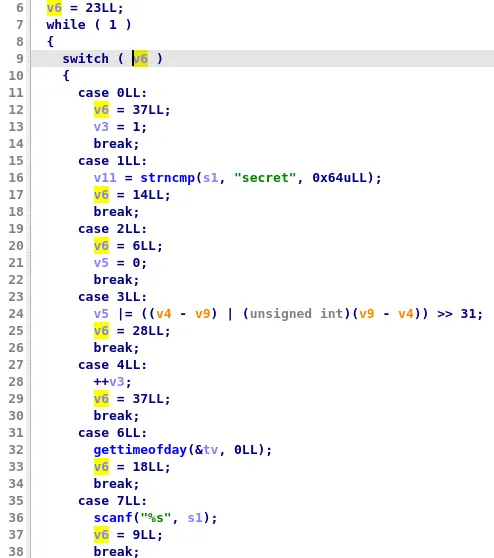
Here are a few things that will slow down the analysis of this function:
Even if the graph of the function obfuscated with the three control flow flattening techniques described before look very differents, they all share several common elements:
However, depending on which obfuscator you are using, the way these elements are used will change:
Removing control flow flattening is not a new topic and there are several very well written blog post which explains in great details how it can be done:
To summarize, the strategy to unflatten a function is relatively simple:
However, life is not that simple and multiple problems can happen:
Initially, we tried to develop a generic rule which could deal with all control flow flattening techniques, but we failed :). However, we identified several features that we were using almost all the time:
Before explaining these techniques, let's have a quick look at the relevant parts of the Hex-Rays microcode API.
Hex-Rays published its microcode API several years ago and at the same time, they allowed us to hook the decompilation process. Thanks to this API, we can remove several obfuscation layers during decompilation.
More precisely, there are two type of callbacks that we can use:
optinsn_t is mostly used to perform optimization at the instruction layer. This is what we demonstrated in our previous blog postoptblock_t can be used to analyze and modify function blocks. This is what we are using to remove control flow flattening.When we are optimizing microcode instructions, we are dealing with the following 2 data structures:
minsn_t: a microcode instruction which contains (up to) three operandsmop_t: an operand used in a microcode instruction. It can be a number, a register, a stack variable or even a microcode instructionWhen we are optimizing the control flow of a function, we are also using 2 other data structures:
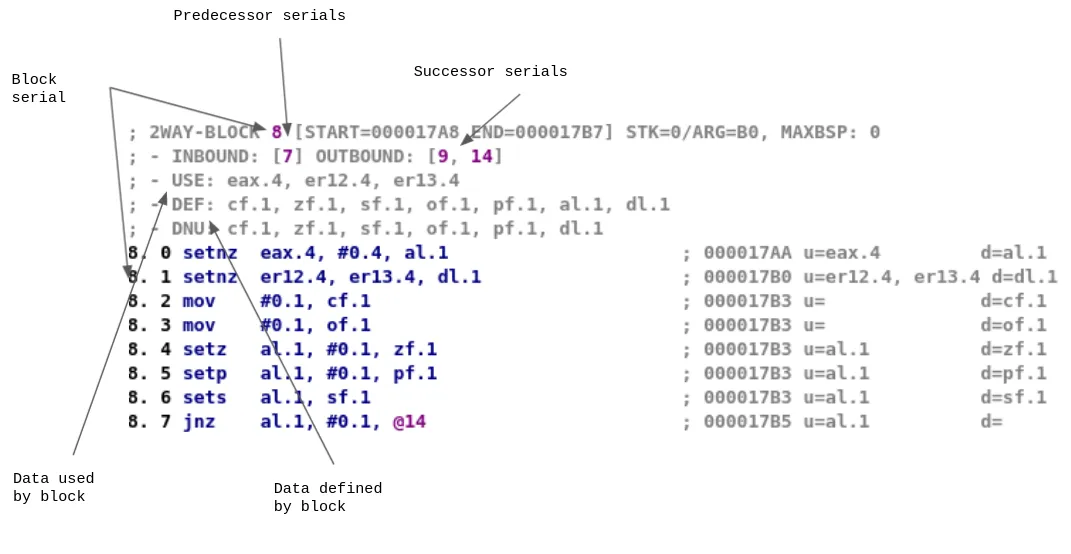
mblock_t: a basic block of a functionmba_t: a structure which contains all blocks of a functionIn each mblock_t, we can find information about:
mba_t, referred to as block serial
This information can be visualized using tools such as lucid:
So, in order to remove the control flow flattening of a function, D-810 will register an optblock_t callback and inspect and modify mblock_t blocks.
In order to unflatten a function, we have to recover the value of the state variable at the end of each block. Our strategy for this part was to locate the instructions which are involved in the computation of this state variable.
Fortunately, Hex-Rays microcode API can be used to determine if an instruction is used to compute a variable. Thus, we can use this API and walk backwards through a block (and its predecessors) to find the instructions used to define the variable.
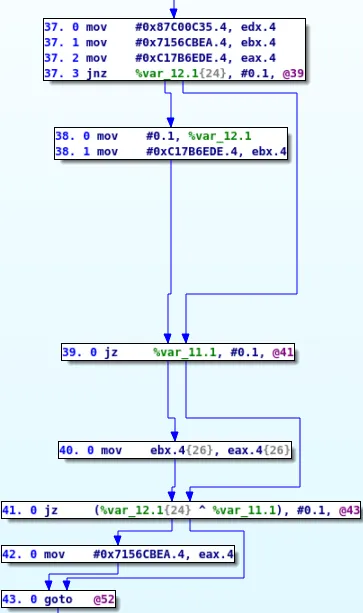
For instance, here is the entry block of the dispatcher:
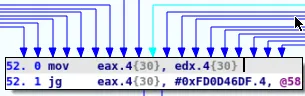
eax.4 register is used as a state variable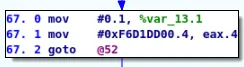
To deal with such cases, we have to be able to recursively search for the definition of other variables.
In the previous example case, our algorithm will start from block 43 and try to find the possible values of eax.4. Since there is no instruction used to compute eax.4 in block 43, we will search in its predecessors (blocks 42 and 41)
eax.4 value is set to 0x7156CBEA, thus we can stopeax.4 is not specified thus we have to look into its predecessor (block 40 and 39)eax.4 is set to ebx.4, thus we need to continue searching for the definition of ebx.4 instead of eax.4eax.4 and must continue our search in its predecessors.In the end, our algorithm will output the 5 possible ways the eax.4 variable can be computed:
-> 42. 0 mov #0x7156CBEA.4, eax.4 -> 43.
-> 38. 1 mov #0xC17B6EDE.4, ebx.4 -> 39.
-> 40. 0 mov ebx.4, eax.4 -> 41. -> 43.
-> 37. 1 mov #0x7156CBEA.4, ebx.4 -> 39.
-> 40. 0 mov ebx.4, eax.4 -> 41. -> 43.
-> 37. 2 mov #0xC17B6EDE.4, eax.4 -> 38. -> 39. -> 41. -> 43.
-> 37. 2 mov #0xC17B6EDE.4, eax.4 -> 39. -> 41. -> 43.
Our implementation of this algorithm can be found in our MopTracker class and it was initially based on the code of Rolf Rolles. However we wanted to be able to deal with more complex cases:
The first part was relatively easy to do as we just had to perform backward tracking on a list of variables.
When we encounter a microcode instruction which defines the variable(s) we are looking for, we just have to update the list and continue the search.
For instance, if we are tracking the variables [eax.4] and we face the microcode instruction add ebx.4, ecx.4, eax.4, then we will remove eax.4 from the list of variables and add ebx.4 and ecx.4 to it. Hence, we will continue the backward variable tracking on [ebx.4, ecx.4].
Note that actual computation of the state variable is performed by the microcode interpreter of D-810 that we describe in the next section.
Dealing with memory assignment is another beast. Due to memory aliasing, a lot of things can go wrong. Thus, we only have partial support for this type of microcode operation and we give an example of that in the practical showcase on Tigress unflattening.
Using our MopTracker class, we are able to find the instructions used to compute the state variable at the end of a block. In order to compute its value, we created a Microcode emulator which allows us to evaluate any microcode instruction.
This component is split into two classes:
Using it, we can execute the instructions found by our MopTracker to compute the value of the state variablefor any path used.
We also use this microcode interpreter to emulate the dispatcher and to find out what was the serial of the next block to execute:
Once all this analysis is done, we must patch the microcode to remove the control flow flattening.
If the state variable at the end of a block that has only one possible value, we can easily recover the serial of the next block to execute by emulating the dispatcher as demonstrated in the previous section.
Then, we just have to replace the jump to the dispatcher by a jump to the unflattened block.
However, when a block has multiple possible values for the state variable it can become quite complex.
For instance, let's go back to the previous example where the state variable is eax and the dispatcher entry block is the block with serial 52:
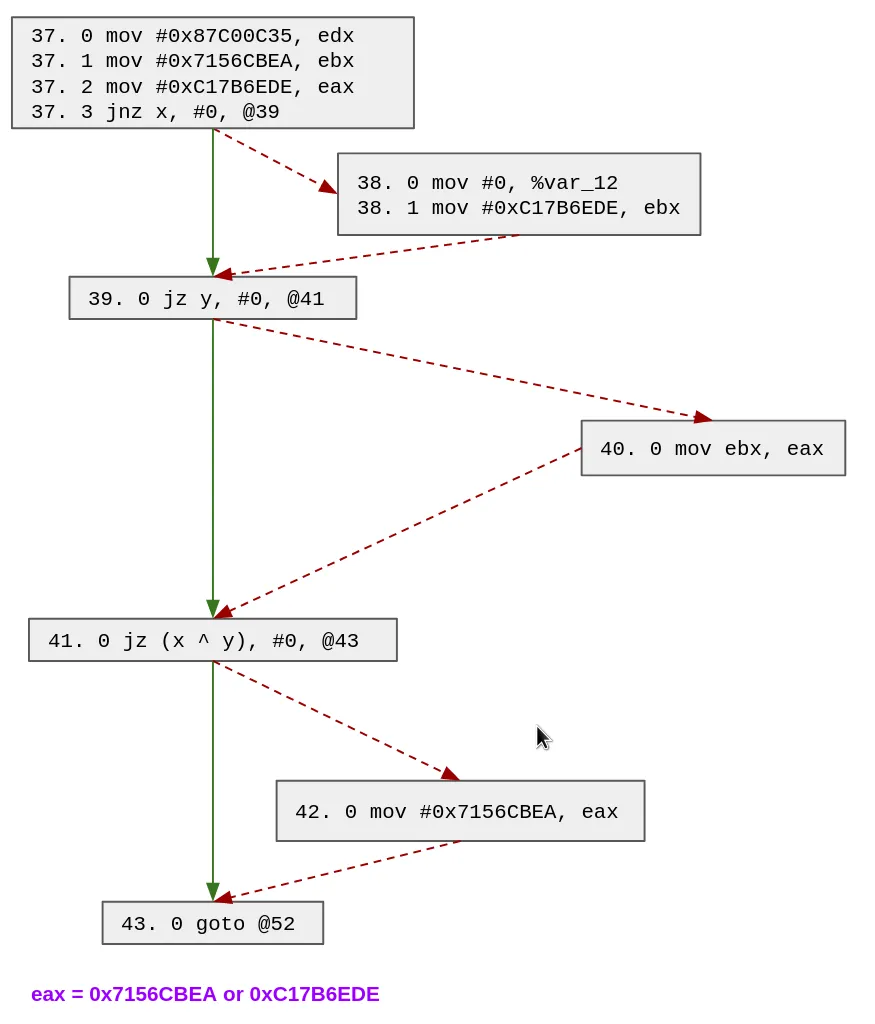
To deal with such cases, we duplicate several blocks of the function to ensure we are back in the simple case (i.e. with only one possible value for the state variable).
We use the output of our MopTracker to find out which block we should duplicate. The main idea of our algorithm is to duplicate any block which appears in (at least) 2 paths with (at least) 2 different predecessors. By doing that recursively, we will ensure that all blocks that jump to the dispatcher will have only one possible value for the state variable.
This is performed by the duplicate_histories function.
Let's see how it works in this example. As a reminder, we already shown how D-810 MopTracker was able to find the 5 possible paths which can define eax:
42 -> 43
38 -> 39 -> 40 -> 41 -> 43
37 -> 39 -> 40 -> 41 -> 43
37 -> 38 -> 39 -> 41 -> 43
37 -> 39 -> 41 -> 43
We look for a block which appears in (at least) 2 paths with (at least) 2 different predecessors:
We can choose any of these blocks, so let's choose block 39. Note that because the block 39 ends with a conditional block we must create 2 blocks:
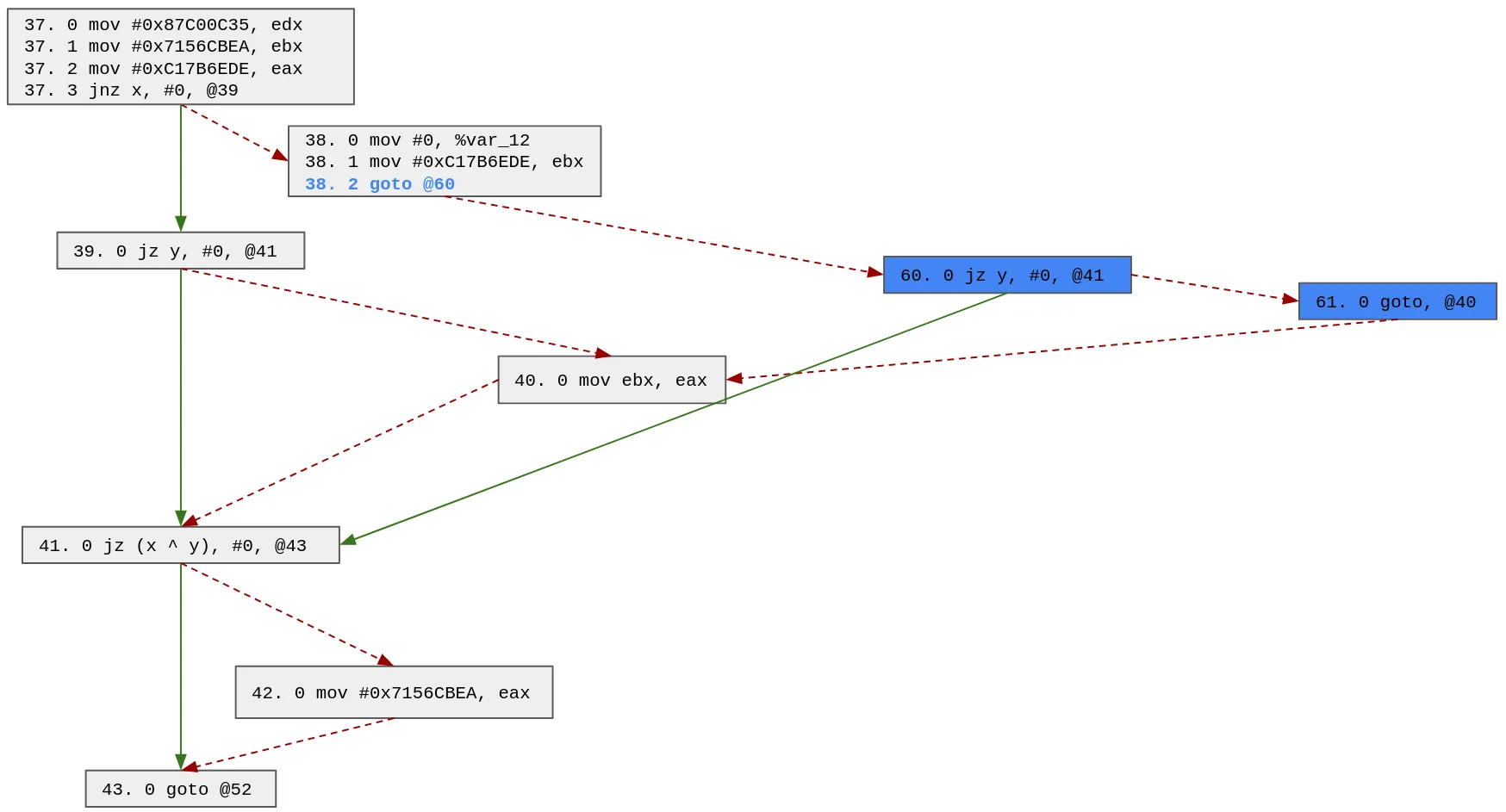
We can update the possible paths with this patch and search for the next block to duplicate:
42 -> 43
38 -> 60 -> 61 -> 40 -> 41 -> 43
37 -> 39 -> 40 -> 41 -> 43
37 -> 38 -> 60 -> 41 -> 43
37 -> 39 -> 41 -> 43
Based on the updated possible paths, we will duplicate block 40 (we also could have chosen block 41 or 43). Note that since it is a one way block, we only need to create 1 block (70):
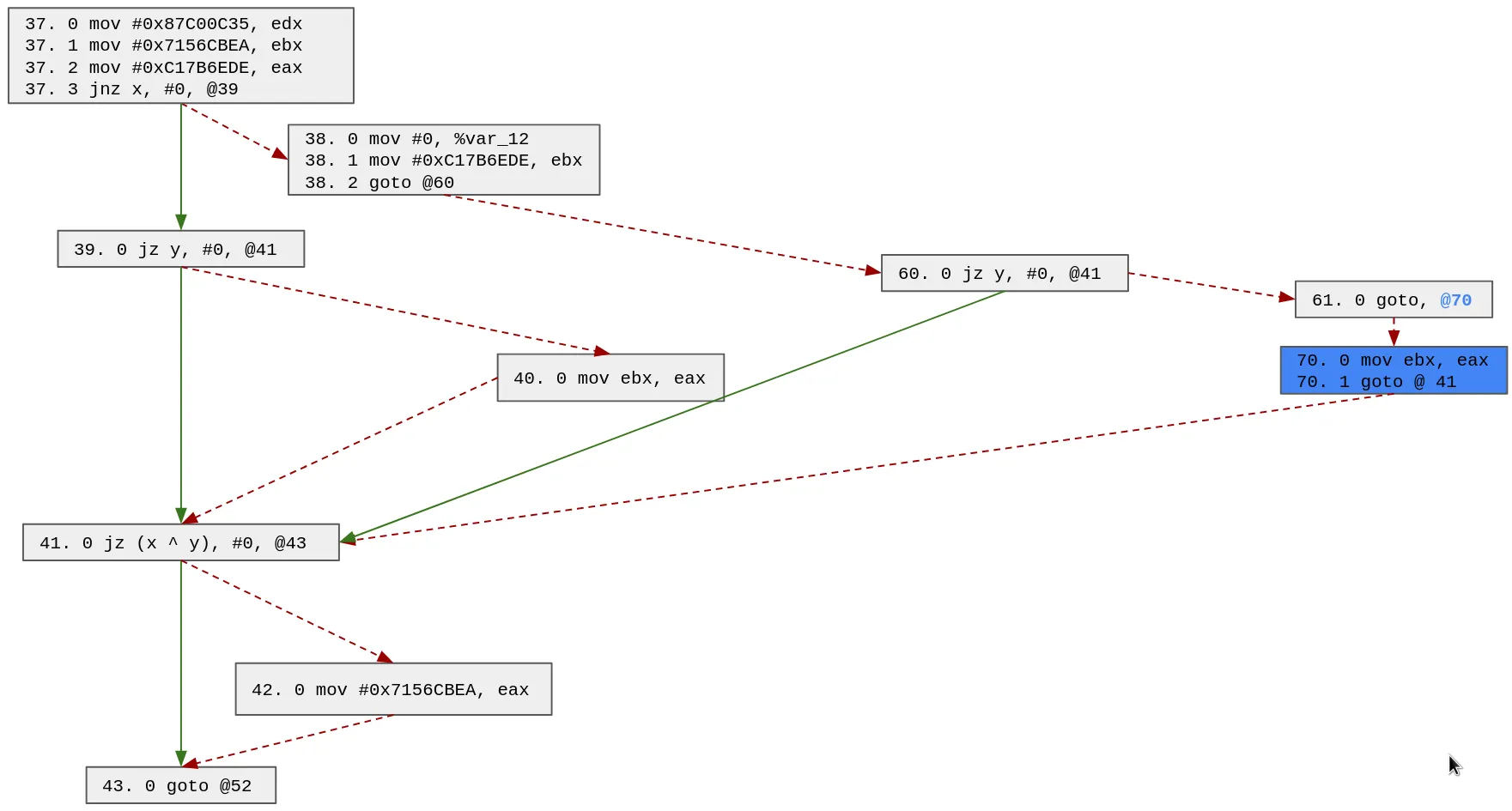
We can update the possible paths with this patch and search for the next block to duplicate:
42 -> 43
38 -> 60 -> 61 -> 70 -> 41 -> 43
37 -> 39 -> 40 -> 41 -> 43
37 -> 38 -> 60 -> 41 -> 43
37 -> 39 -> 41 -> 43
Based on the updated possible paths, we will duplicate block 41 (we also could have chosen block 43). Note that the block 41 has 4 possible predecessors (70, 40, 60 and 39), thus we need to clone it 3 times:
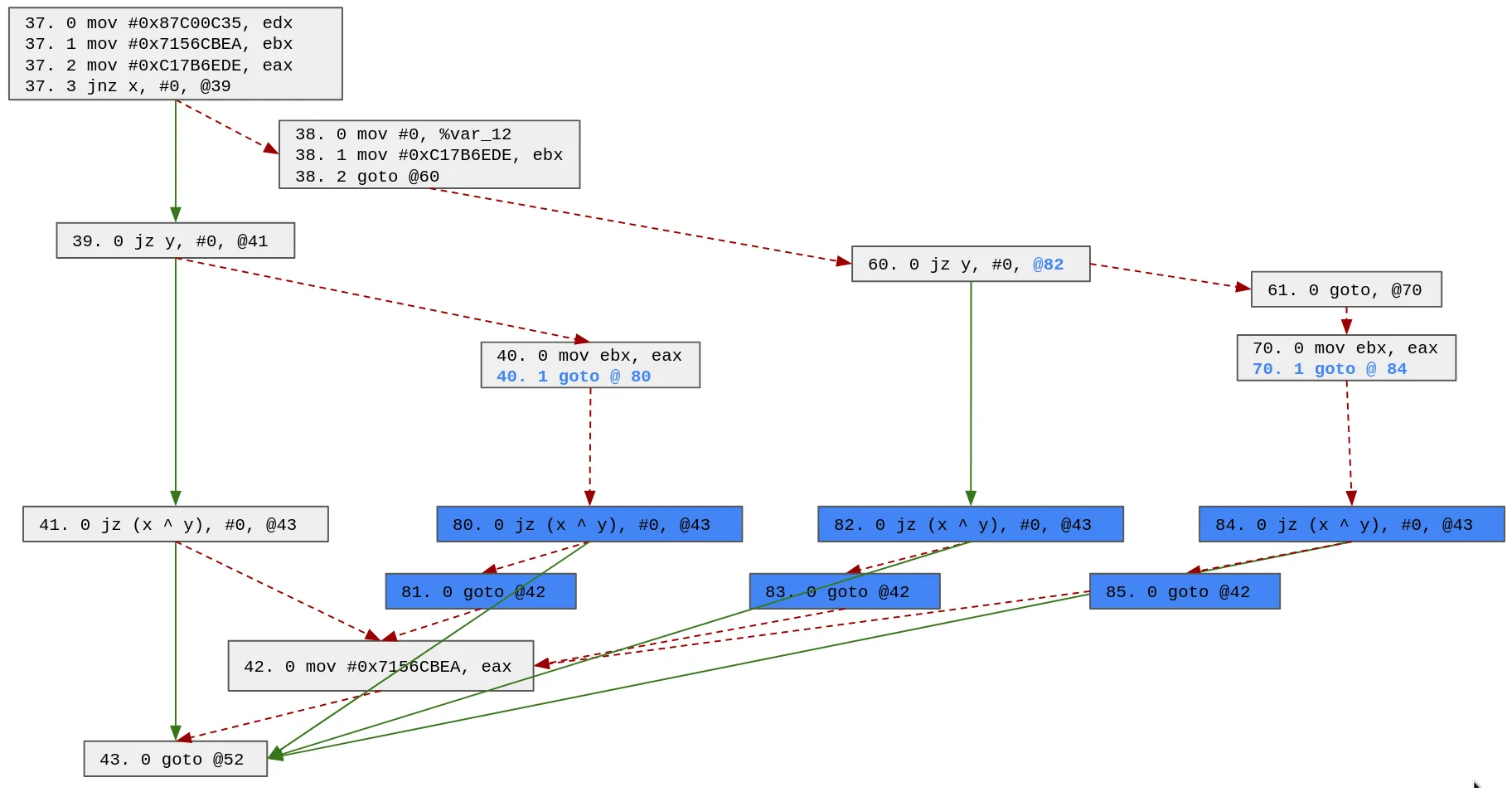
At this point in time, the possible paths look like this:
42 -> 43
38 -> 60 -> 61 -> 70 -> 84 -> 43
37 -> 39 -> 40 -> 80 -> 43
37 -> 38 -> 60 -> 82 -> 43
37 -> 39 -> 41 -> 43
The only remaining block to duplicate is the block 43. Indeed, even if block 42 has multiple predecessors, it appears only once in the possible paths, thus we do not need to duplicate it.
In the end, we end up with the following control flow:
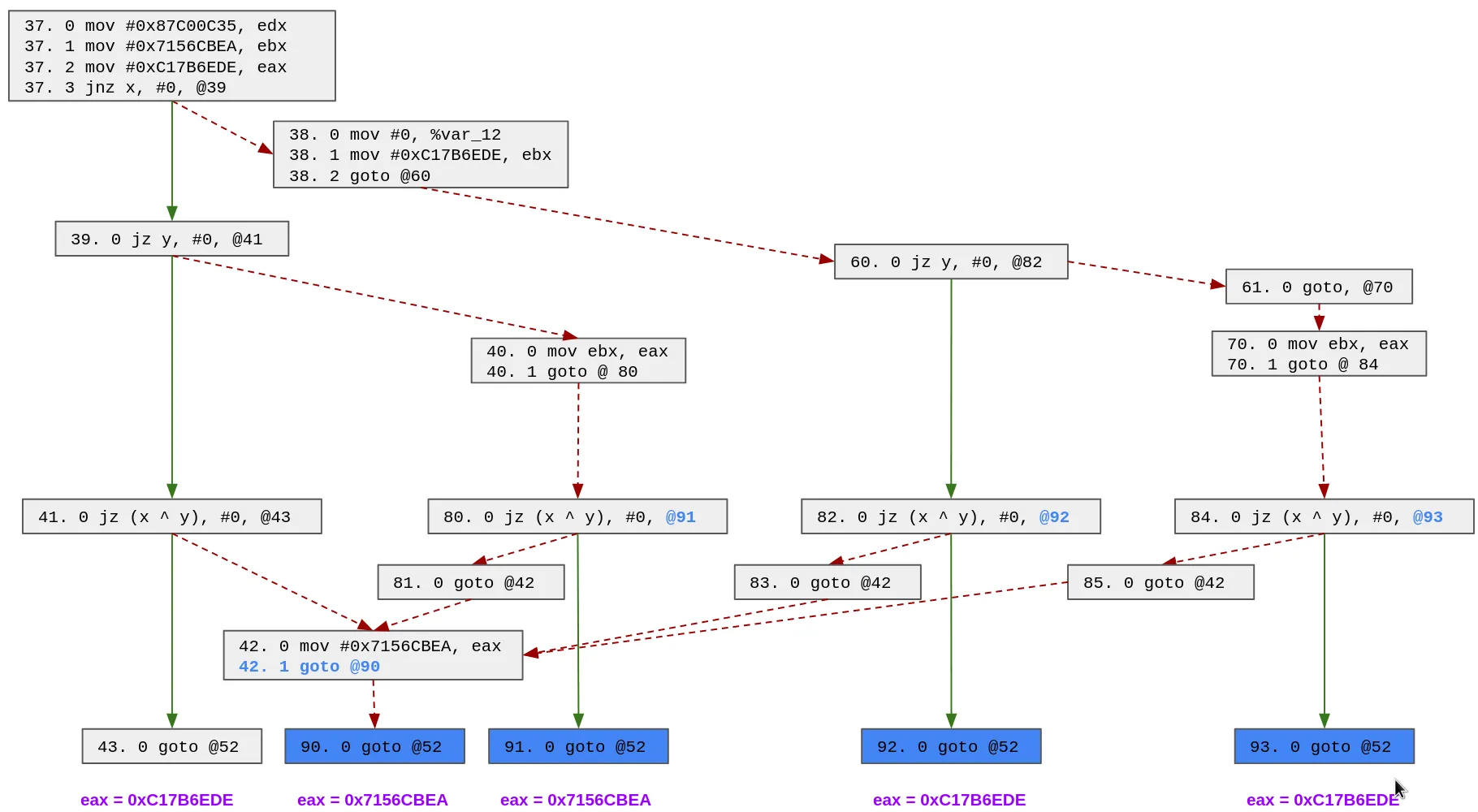
Now, we are back in the simple case, at the end of each block (43, 90, 91, 92 and 93), the state variable has only one possible value and we can patch it easily.
The main advantage of this approach is that it is generic and can be used to transform the graph of the function into something that we can simplify. However, one downside is that we may end up duplicating a lot of code in some weird cases.
Using these three features of D-810, we were able to remove most of the control flow flattening techniques we encountered.
Most of the code unflattening currently implemented in D-810 relies on the GenericDispatcherUnflatteningRule rule and the process is the following:
While we were able to remove most of the code flattening techniques that we encounter up until now, we believe that there is quite a room for improvement in the current solution:
For O-LLVM flattening, no configuration is needed and D-810 should be able to simplify the code directly. However, for other obfuscators, it is not always straightforward. So, we decided to showcase how we can configure D-810 to help it deobfuscate the code generated using Tigress Flatten transformation with:
We also decided to use the Tigress Encode Arithmetic transformation to add complexity to the original function and make things a bit more interesting.
For the function to obfuscate we generated a function using Tigress Random Function feature and we modified it a bit to add constant obfuscation. The original source code of the function (and its obfuscated version) can be found here. The binary used in this example can be found here.
Let's see how it looks when we reverse engineer the function protected with this technique.
When we open the protected binary in IDA Pro, we can quickly see that the function is not correctly identified:
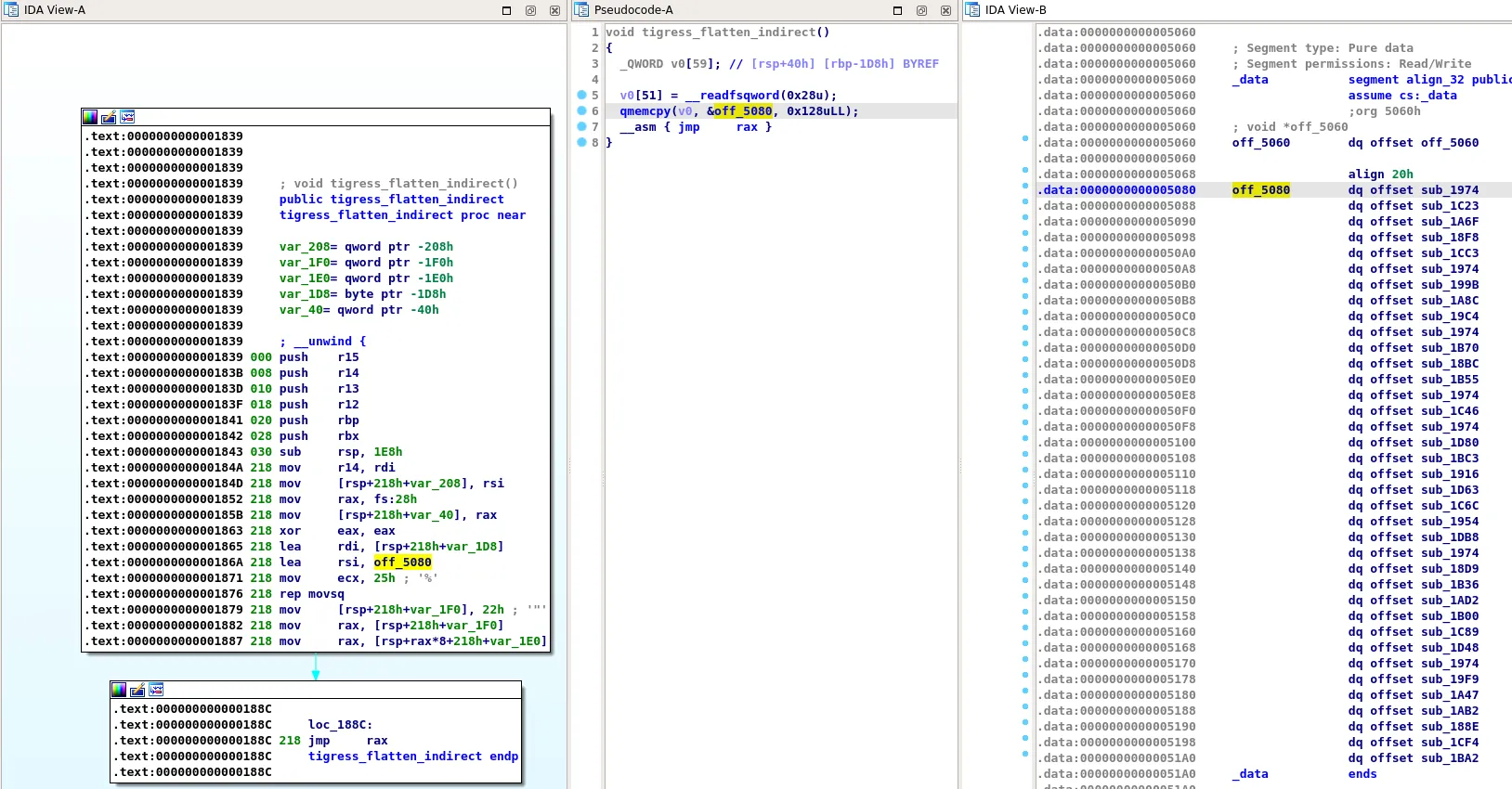
We noticed that IDA Pro initial analysis created a function for each of the basic blocks of the original function and their addresses are stored at address 0x5080 (in a RW segment).
Additionally, because of the jmp rax instruction at address 0x188c, IDA Pro can't find the next block to execute and considers this is the end of the function. Note that this is expected and we can't blame IDA for that:
So, the first thing we need to do is to delete the incorrect functions and fix the tigress_flatten_indirect function bounds.
It can be done with the following script:
from idaapi import get_qword, del_func, add_func
flattened_function_info = {
"start_ea": 0x1839,
"end_ea": 0x1DDD,
"jump_table_ea": 0x5080,
"jump_table_nb_elt": 37
}
# IDA creates function for each jump table entry => we need to remove them
for i in range(flattened_function_info["jump_table_nb_elt"]):
label_ea = get_qword(flattened_function_info["jump_table_ea"] + 8 * i)
del_func(label_ea)
# If we create the function manually, its end won't be correct, so we explicitly specify its end
del_func(flattened_function_info["start_ea"])
add_func(flattened_function_info["start_ea"], flattened_function_info["end_ea"] + 1)
Now, the function bounds are correct but we are facing a new issue that will prevent us from removing the control flow flattening:
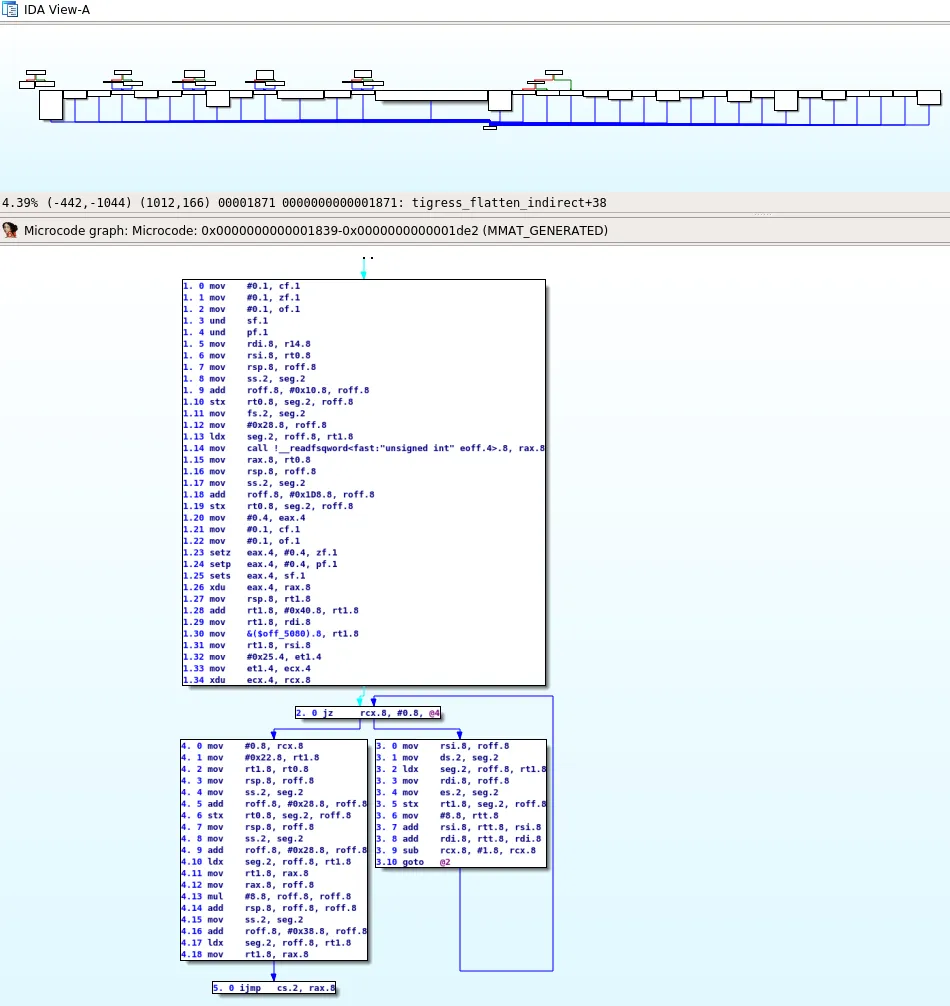
During the decompilation process, the Hex-Rays microcode evolves and these levels of evolution are called maturity. In the previous image, we show the microcode generated in the lowest maturity (MMAT_GENERATED). The issue that we can observe is that this microcode only includes the basic blocks before the jmp rax instruction. We believe that this is because IDA Pro does not see a path between the other blocks and the entry point of the function and thus considers them as dead code and does not bother decompiling them.
Therefore, we must trick IDA into decompiling them and we will do that by adding cross reference between the jmp rax instruction and all the other blocks of the jump table. We can do that using the following script which will create cross references between the dispatcher and all flattened blocks:
from idaapi import get_qword, add_cref, fl_JN
flattened_function_info = {
"start_ea": 0x1839,
"end_ea": 0x1DDD,
"jump_table_ea": 0x5080,
"jump_table_nb_elt": 37,
"jump_rax_ea": 0x188C
}
for i in range(flattened_function_info["jump_table_nb_elt"]):
label_ea = get_qword(flattened_function_info["jump_table_ea"] + 8 * i)
x = add_cref(flattened_function_info["jump_rax_ea"], int(label_ea), fl_JN)
print(x)
print("Adding cref from {0:x} to {1:x}".format(flattened_function_info["jump_rax_ea"], label_ea))
Now that we created those "fake" cross references, all blocks will be decompiled by IDA Pro and we can start our work.
Note that at the end of maturity MMAT_LOCOPT, IDA Pro will see that these blocks are not reachable and will remove them. Thus, D-810 rule needs to be applied at maturity MMAT_LOCOPT.
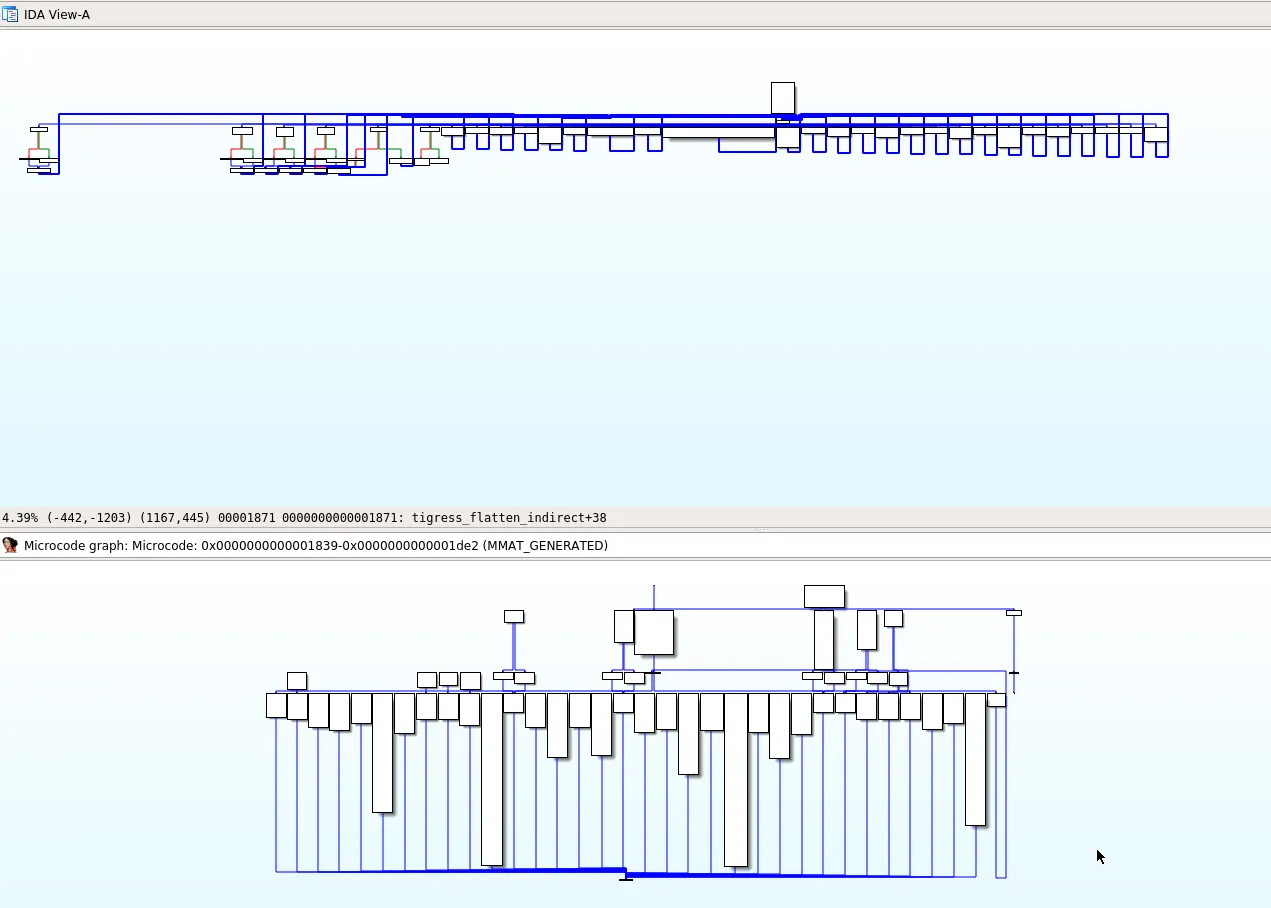
D-810 includes a rule UnflattenerTigressIndirect which deals with this technique of control flow flattening. However, we need to configure it in order to work properly.
As explained before, the jump table used by the dispatcher is copied into a stack variable at the beginning of the function, which translates to the following microcode (at maturity MMAT_LOCOPT):
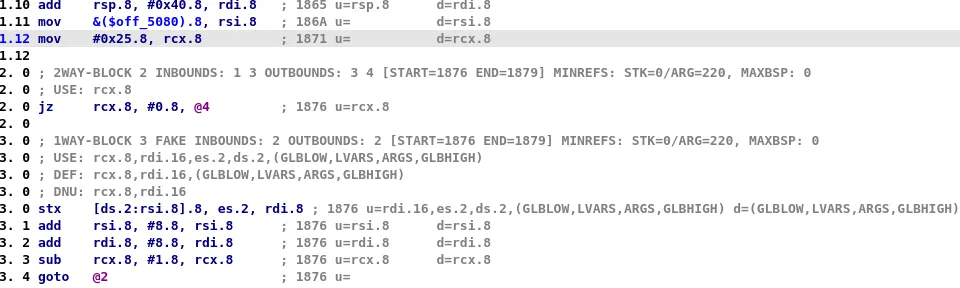
rdi is set to rsp + 0x40rsi is set to &($off_5080) (the jump table stored in the .data section)rcx is set to 0x25 (the number of element of the jump table)rsp + 0x40
Then, at the end of each block the address of the next block is recovered using a pattern similar to this one:
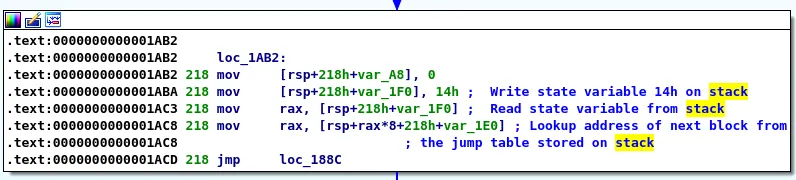
At maturity MMAT_LOCOPT, IDA Pro will already have performed some optimization and the microcode will look like that:

In order to find the value of the state variable (rax) at the end of the block 26, D-810 will use its MopTracker, which will fail because there is no direct assignment of stack variable %0xD8.8.
This is linked to the fact that this value is accessed indirectly in the initial loop (blocks 1, 2 and 3).
Currently D-810 is not able to identify that automatically. However, we can tell it what the initial value of the stack is when this function is called.
In order to configure the UnflattenerTigressIndirect rule, we need to specify:
This can be done by editing the rule configuration file of D-810:
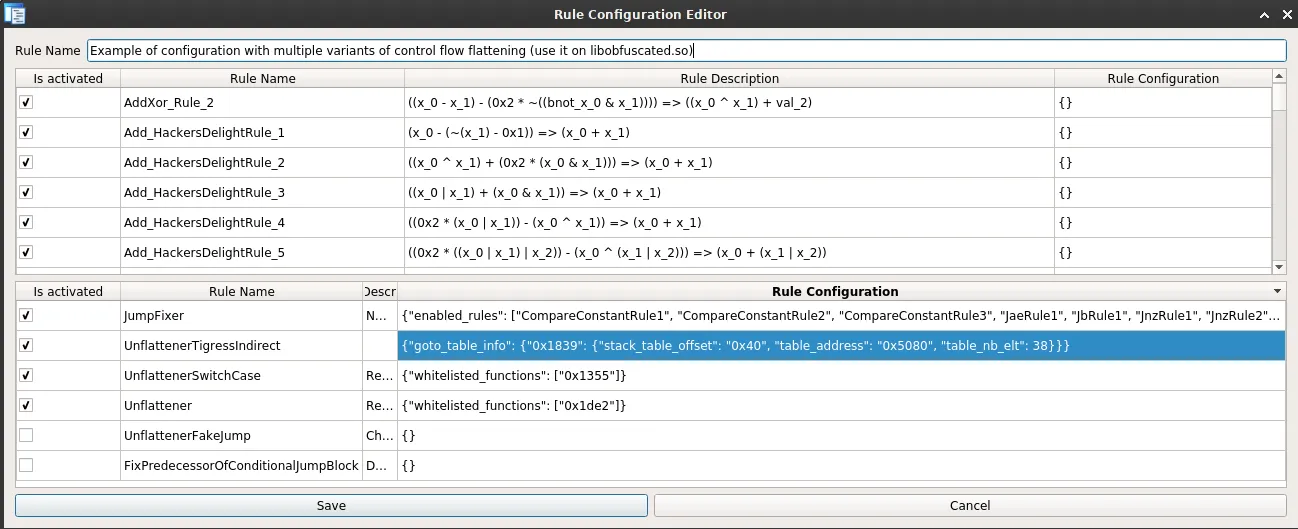
In practice, the rule will use this information to create a mop (microinstruction operand) located at the appropriate stack offset and tell the MopTracker that this mop is equal to the data stored in the table stored in the RW segment.
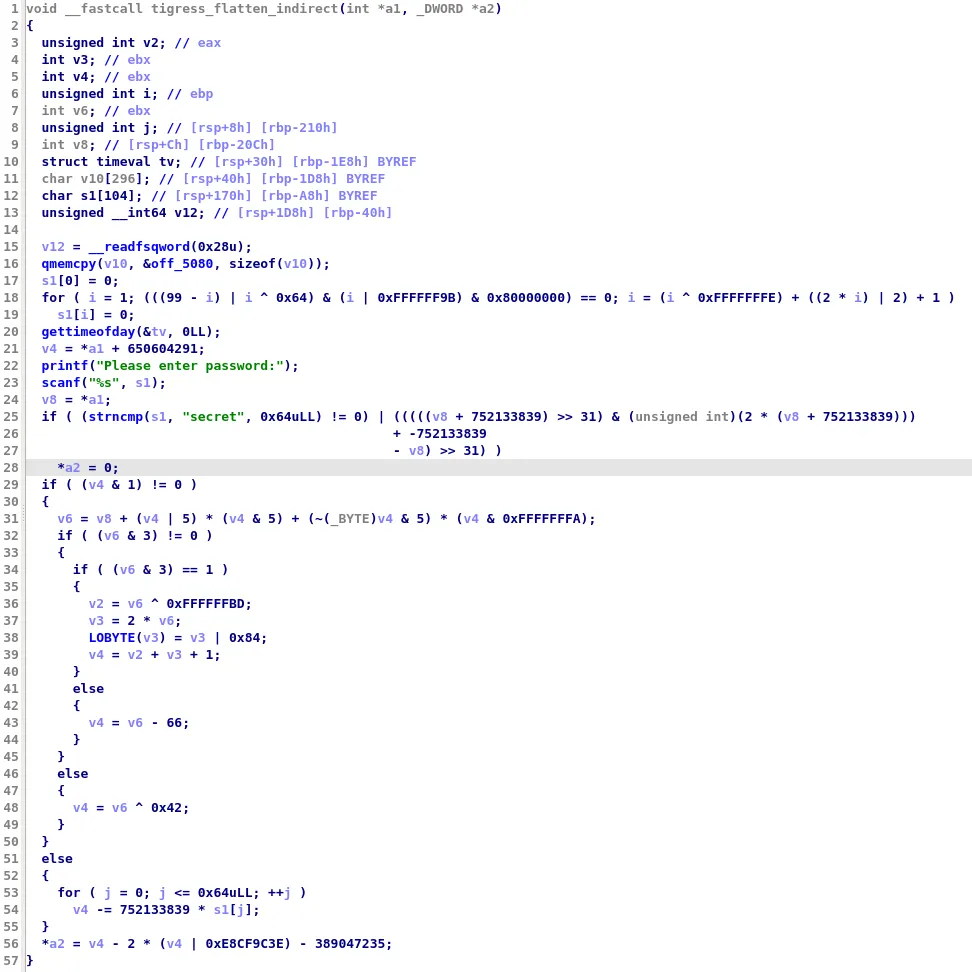
Once this is done, D-810 will be able to remove the control flow flattening protection and we will have a much cleaner function:
In this blog post, we described some of the techniques used by D-810 to remove control flow obfuscation. As explained in this blog post, we do not have a generic method that will allow us to remove all possible control flow flattening techniques without any manual work.
However, D-810 implements several features which can be used to quickly develop new rules when we are facing a new obfuscation technique.
We are still investigating new techniques such as symbolic execution that could allow us to achieve better results.
Some final disclaimers:
Rolf Rolles for his HexRaysDeob plugin and his blog post. The current code of our plugin uses ideas (and code) from his work.
Dennis Elser for his genmc plugin and Markus Gaasedelen for lucid which helped us analyze microcode at various maturity levels.
Tigress C obfuscator and O-LLVM for providing awesome free obfuscators and allowed us to try D-810 on multiple obfuscation techniques.
Thanks to Tiana and Yorick for their review of this blog post and our discussion around D-810!




